|
|
Informationstechnik
Labor Swimming Pixel - Mikro Funkstrecken |
Wintersemester 20/21 fejo1020@hs-karlsruhe.de esma1014@hs-karlsruhe.de |
|
|
Informationstechnik
Labor Swimming Pixel - Mikro Funkstrecken |
Wintersemester 20/21 fejo1020@hs-karlsruhe.de esma1014@hs-karlsruhe.de |
|
|||
| In dem vorausgehenden Projekt "Ortungssystem
für Swimming-Pixel" im Wintersemester 2019 wurden verschiedene
Alternativen zur Positionsbestimmung evaluiert. Zur Durchführung der
Positionsbestimmung hat sich das sogenannte "Spiegel-Prinzp" als
erfolgversprechendste Verfahren herausgestellt. Grundlagen Spiegel-Prinzip Beim "Spiegel-Prinzp" wird ein akustisches Signal von am Host befindlichen Lautsprechern gesendet. Diese Signale werden von einem Mikrofon auf dem Pixel detektiert und als RF-Signal an den Host zurück gesendet. Das vom Mikrofon aufgezeichnete Signal besteht aus einer Überlagerung der akustischen Signale der beiden Lautsprecher und Störsignalen wie zum Beispiel Rauschen oder anderweitige Umgebungsgeräusche. Zur Auswertung dieses Audiosignals wird das Verfahren der Kreuz-Korrelation verwendet. 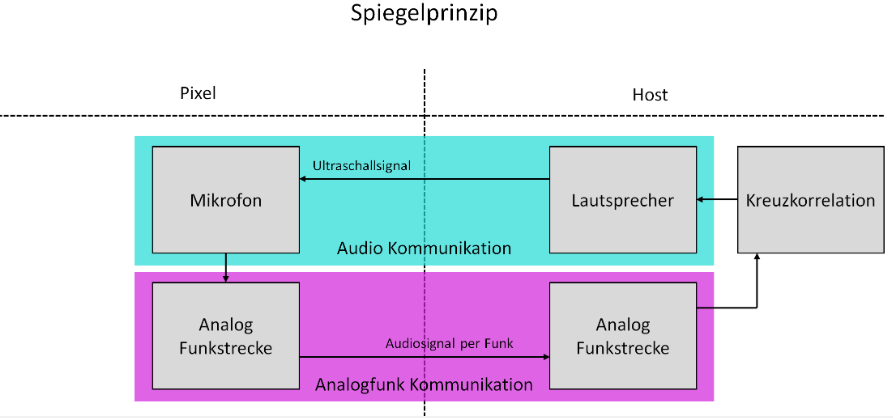 Abb.: Spiegelprinzip Versuchsaufbau Zur Umsetzung des Projekts wird zunächst ein Konzept entwickelt. Dieses wird in der nachfolgenden Abbildung "Skizze Versuchsaufbau" grob veranschaulicht. Der Versuchsaufbau besteht grundsätzlich aus einem PC als Host und mehreren Pixeln als Clienten. Beide Systeme sind komplett eigenständig und räumlich voneinander getrennt. Zum Datenaustausch kommunizieren die Pixel mit dem Host und umgekehrt über eine WiFi-Verbindung. Die beiden Funk- und Empfangsmodule sind in der Skizze mit den Nummern 2 und 3 gekennzeichnet. Am Host sind Lautsprecher montiert, welche in einem definierten Abstand voneinander aufgestellt werden. Bei den Lautsprechern handelt es sich um Hochtöner um Frequenzen im Ultaschallbereich auszusenden. Diese sind in der Skizze mit der Nummer 1 markiert. Die Swimming Pixel selbst sind als energieautonomer Schwimmkörper umgesetzt. Jeder Pixel besteht aus einem Schwimmkörper, einem LED-Ring, einem Akku, Solarzellen, einem ESP32 Mikrocontroller und eine Mikrofon zur Aufzeichnung der akustischen Signale. 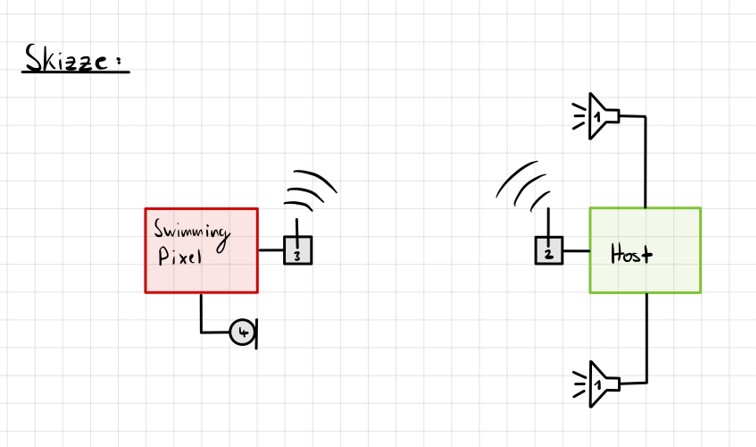 Abb.: Skizze Versuchsaufbau Positionsbestimmung Zur Berechnung der Position eines Pixels wird die durch den Schall zurückgelegte Wegstrecke Y und Z vom linken und rechten Lautsprecher berechnet. Da der Abstand X der beiden Lautsprecher zueinander bekannt ist, kann die Position des Pixels errechnet werden. X = Bekannter Abstand der Lautsprecher Y = Gemessener Weg vom linken Lautsprecher zum Pixel Z = Gemessener Weg vom rechten Lautsprecher zum Pixel 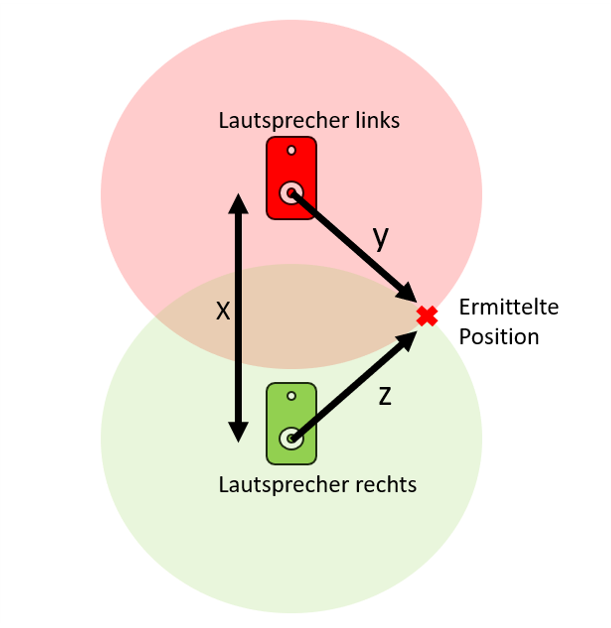 Abb.: Aufbau Gesamtsystem Technische Umsetzung Integrierte AD-Wandler Die Aufzeichnung der Ultraschallsignale soll auf dem Swimming-Pixel mittels eines Mikrofons umgesetzt werden. Um die analogen Signale eines einfachen Mikrofons auslesen zu können, müssen die analogen Werte in digitale Werte gewandelt werden. Da der ESP32 zwei verschiedene AD-Wandler besitzt, wird in einem ersten Versuch zunächst geprüft, ob diese für das Projekt Mikro-Funkstrecken geeignet sind. Der ADC1 besitzt 8 Kanäle, der ADC2 besitzt 10 Kanäle. 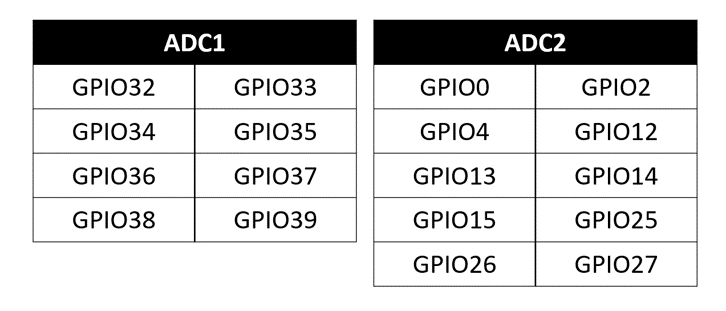 Abb.: Analoge Eingänge ESP32 Da der ADC2 ebenfalls von dem WiFi-Treiber verwendet wird, kann dieser nicht für das Projekt genutzt werden, da ebenfalls eine Kommunikation via WiFi zwischen dem Host und dem Pixel stattfinden soll. Zur einfachen AD-Wandlung mittels ADC1 kann der vom Ardunio bekannte Befehl analogRead() als auch die Funktionen zur AD-Wandlung adc1_get_raw() von Espressif verwendet werden.  Abb.: Befehle für das Einlesen analoger Signale Zur einfachen Überprüfung der Funktionalität des internen AD-Wandlers wird ein Potentiometer an den ESP32 angeschlossen, um die analogen Spannungswerte zu lesen. Es wird hierbei vor allem getestet, ob eine ausreichend hohe Abtastrate erreicht werden kann. Unter Berücksichtigung des Nyquist-Shannon-Abtasttheorems muss die Abtastrate mehr als doppelt so groß sein, wie die maximale Frequenz im Signal. Da in diesem Projekt Frequenzen im Ultraschallbereich von ca. 22 kHz verwendet werden, muss die Abtastrate somit mindestens 44 000 Abtastpunkte / Sekunde betragen. In der nachfolgenden Abbildung ist der Aufbau gezeigt: 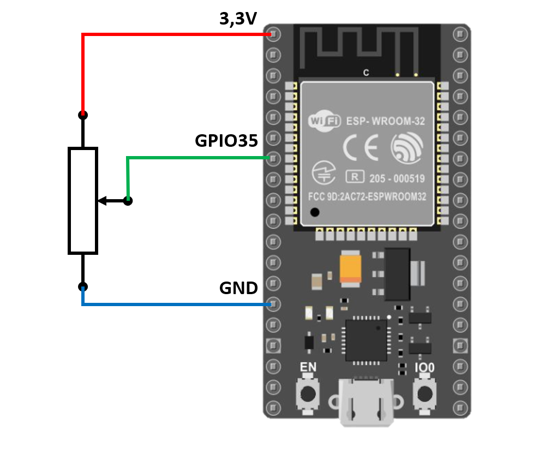 Abb.: Anschluss Poti an ESP32 Trotz einer Vielzahl an unterschiedlichen Umsetzungen kann eine ausreichend hohe Abtastrate mit dem internen ADC1 nicht erreicht werden. Die maximale Abtastrate beträgt 21300 Abtaspunkte / Sekunde. Hiermit wird das Nyquist-Shannon-Abtasttheorems nicht erfüllt und es kommt zu Abtastfehlern durch Aliasing. Ein weiterer Grund, die analogen Signale des Mikrofons nicht mit dem intern AD-Wandler zu konvertieren, liegt in der Auslastung der CPU. Durch die hohe Abtastrate ist die CPU kontinuierlich mit der AD-Wandlung beschäftigt und hat somit wenig Zeit andere Programme auszuführen. Eine Kommunikation über WiFi spiegelt sich, mit einer so stark ausgelasteten CPU, in einer hohen Latenzzeit wieder. Aus den genannten Gründen wird deshalb eine andere Möglichkeit gesucht die analogen Signale des Mikrofons auszulesen. I2S-Bus Der I2S-Bus ist ein Bussystem, welches speziell zur Audiodatenübertragung entwickelt wurde. Verwendet wird er vor allem zur Übertragung von Audio-Informationen zwischen ICs. Ein großer Vorteil dieses Bussystems ist seine sehr hohe Datenrate, die zur Übertragung von Audiodaten benötigt wird. Der Datentransfer über den I2S-Bus erfolgt über drei Leitungen für das Taktsignal (Serial Clock), die Wortauswahl (Word Select) und der Datenleitung (Serial Data). Über die Leitung Serial Clock (SCK) wird ein gemeinsamer Takt zwischen den ICs sichergestellt. Die Word Select (WS) Leitung signalisiert den Start und die Dauer eines übertragenen Datenworts, und über die Serial Data (SD) Leitung werden die eigentlichen Audio-Daten gesendet. I2S-Mikrofone verwenden den I2S-Bus, um die Audio-Daten an ein weiteres Gerät zu übertragen. Das Interessante bei diesen Mikrofonen ist, dass diese bereits einen Audio-Verstärker und einen AD-Wandler integriert in ihrem IC besitzen. Die digitalen Daten können somit über den I2S-Bus versendet und direkt vom ESP32 eingelesen werden. Die CPU wird bei diesem Vorgehen nicht mehr konstant durch die AD-Wandlung beansprucht. Nach intensiver Recherche wird das ICS-4343v0.1 I2S MEMS Microphone Breakout Board für dieses Projekt ausgewählt, bestellt und getestet. Alle in diesem Projekt verwendeten Bauteile können der Stückliste entnommen werden. Die nachfolgende Abbildung zeigt das Mikrofon und die entsprechende Pinbelegung am ESP32. Als Versorgungsspannung VDD wird 3,3V verwendet.  Abb.: Anschlussplan Mikrofon an ESP32 Die softwareseitige Konfiguration der I2S Schnittstelle ist etwas aufwändiger. Der nachfolgende Code-Snippet zeigt die vollständige Konfiguration sowie die Pinbelegung. Die wichtigsten Parameter sind hierbei die Abtastrate (sample_rate), die Auflösung (bits_per_sample), das Kanalformat (channel_format), die Anzahl der DMA-Buffer (dma_buf_count) sowie die Größe eines einzelnen DMA-Buffers (dma_buf_len). Auf die Rolle der DMA-Buffer wir nachfolgend noch etwas genauer eingegangen. Für die I2S-Kommunikation werden die Pins GPIO32 für die Serial Clock Leitung, GPIO25 für die Word Select Leitung und GPIO33 für die Serial Data Leitung am ESP32 verwendet. 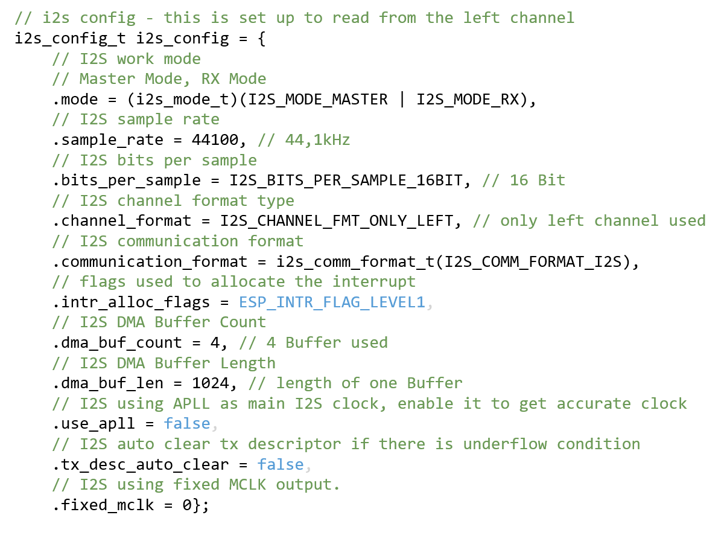 Abb.: I2S-Bus Config  Abb.: I2S Portbelegung am ESP32 Der vollständige Programmcode kann der folgenden Ordnerstruktur entnommen werden. Zur Auswertung der aufgezeichneten Audio-Daten werden diese zu Testzwecken zunächst über einen Node-Server und dem HTTP Protokoll an einen PC gesendet. Der Programmcode für den ESP32 befindet sich in den beiden Ordnern Code_Client_1 und Code_Client_2. Die beiden Inhalte der Ordner müssen in einem neuen Ordner zusammengefügt werden. Da der Programmcode für den ESP32 die maximale Upload Größe der Webseite überschreitet, musste der Inhalt auf zwei Order aufgeteilt werden. Der Programmcode für den PC befindet sich im Ordner Code_Server. Im späteren Verlauf des Projekts soll das Netzwerkprotokoll MQTT verwendet werden. Zur Programmierung wird die Open-Source-IDE Visual Studio Code mit der Erweiterung PlatformIO verwendet. Die PlatformIO ist eine kostenlose Alternative zur Arduino-IDE für die Mikrocontroller-Entwicklung. DMA-Buffer In diesem Abschnitt wird kurz auf die Funktion des DMA-Buffers eingegangen, da dieser in Kombination mit dem I2S-Bus eine wichtige Rolle bei der Audio-Datenübertragung spielt. DMA steht für Direct Memory Access und bedeutet übersetzt "direkter Speicherzugriff". Unter DMA ist eine Schaltungs- und Steuermaßnahme zu verstehen, die über spezielle Datenleitungen eine Verbindung zwischen Ein- und Ausgabeeinheit und dem Arbeitsspeicher herstellen. Dadurch können Daten ohne Umweg über den Prozessor direkt in den Speicher geschrieben werden. So lässt sich die Ausführungsgeschwindigkeit des Gesamtsystems deutlich erhöhen. Gerade bei der Übertragung von Audio-Daten im hohen Frequenzbereich und hoher Abtastrate, kann durch die Verwendung eines DMA-Buffers die CPU-Last deutlich reduziert werden. In dem Code auf dem ESP32 werden, wie in der Konfiguration des I2S-Bus ersichtlich, vier DMA Buffer mit eine Größe von jeweils 1024. Die Gesmatspeichergröße des DMA-Buffers berechnet sich aus der folgenden Formel: Memory consumption = (bits_per_sample / 8) * number_of_channels * dma_buf_count * dma_buf_length Memory consumption = (16Bit / 8) * 1 * 4 * 1024 = 8192 Byte Der Schreibe- und Lesezugriff auf die vier Buffer ist so organisiert, dass die Audio-Daten vom Mikrofon so lange in einen Buffer geschrieben werden, bis dieser voll ist. Im Anschluss wird der volle Buffer durch einen leeren ersetzt und die Audio-Daten des vollen Buffers werden über WiFi an den PC übertragen. Zur Synchronisation des Schreibe- und Lesezugriffs auf die Buffer wird eine Binary Semaphore verwendet. Datenübertragung ESP32 --> PC Die vom Mikrofon aufgezeichneten Audio-Daten werden aus dem DMA-Buffer ausgelesen und über ein lokales WiFi Netzwerk auf den PC übertragen. Eine Übermittlung der Daten auf den PC ist notwendig, da die Audio-Files im späteren Verlauf den Projekts analysiert werden sollen. Da der ESP32 keine ausreichende Rechenleistung besitzt, muss die Analyse auf einem PC erfolgen. Um die Daten in dem lokalen Netzwerk zu senden, wird auf dem PC ein Node-Server eingerichtet. Als Netzwerkprotokoll wird zunächst für Test-Zwecke das HTTP Protokoll verwendet. Im späteren Verlauf des Projekts soll das Netzwerkprotokoll MQTT benutzt werden. Die übertragenen Daten werden auf dem PC als RAW-Datei gespeichert. Erste übertragene Audio-Datei Um die übertragene Audio-Datei im RAW-Format anhören und bearbeiten zu können, muss diese zunächst konvertiert werden. Aus Kompatibiliätsgründen für die spätere Analyse wird die Audio-Datei in das WAV-Format konvertiert. Dies kann direkt in der kostenlosen Software Audacity erfolgen. Das nachfolgende Bild zeigt einen Auschnitt der Software, nachdem die Audio-Datei bereits konvertiert wurde. Überraschend ist hierbei die sehr gute Soundqualität der mit dem Mikrofon aufgezeichneten Audio-Datei. Der Sound ist klar und das Rauschen sehr gering. 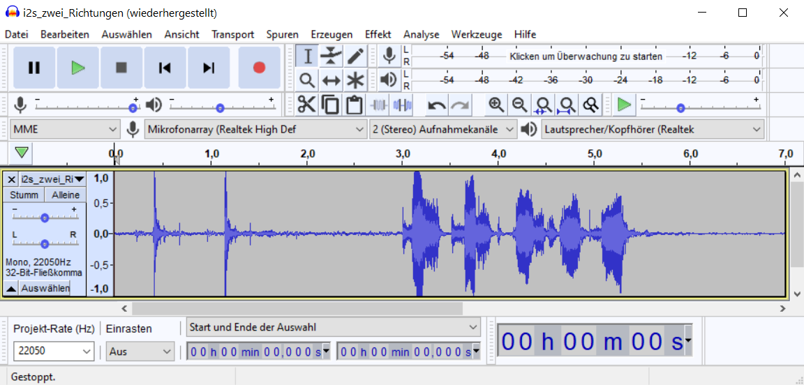 Abb.: Soundtrack Mikrofonaufzeichnung mit Audacity Sound_Track.mp3 In diesem Soudtrack sind zunächst zwei Tastendrücke zu hören, bevor testweise gesprochen wird. Im gleichen Zuge wird in diesem Soundtrack die Mikrofon Richtcharakteristik geprüft. Laut Hersteller besitzt das MEMS Mikrofon eine omnidirektionale Ausrichtung. Der erste Testspruch "Test Test 1-2-3" erfolgt direkt von vorne, der zweite Testspruch "Test Test 2-3-4"erfolgt mit umgedrehten Bread-board. Die Lautstärke des zweiten Testspruchs ist etwas geringer aber noch deutlich zu verstehen. FFT-Analyse Zur Durchführung der FFT-Analyse einer aufgezeichneten Audio-Datei wird ein Jupyter Notebook geschrieben. Der Programmcode ist in dem Ordner Python_FFT abgespeichert. Um die FFT-Analyse zu testen, wird mit dem Mikrofon ein 500 Hz Sound aufgezeichnet. Das Ergebnis der FFT-Analyse wird in den folgenden Bildern präsentiert. Das erste Bild zeigt das gesamte aufgezeichnete Spektrum. Im zweiten Bild wird an den größten Peak herangezoomt, um die Frequenz zu überprüfen. 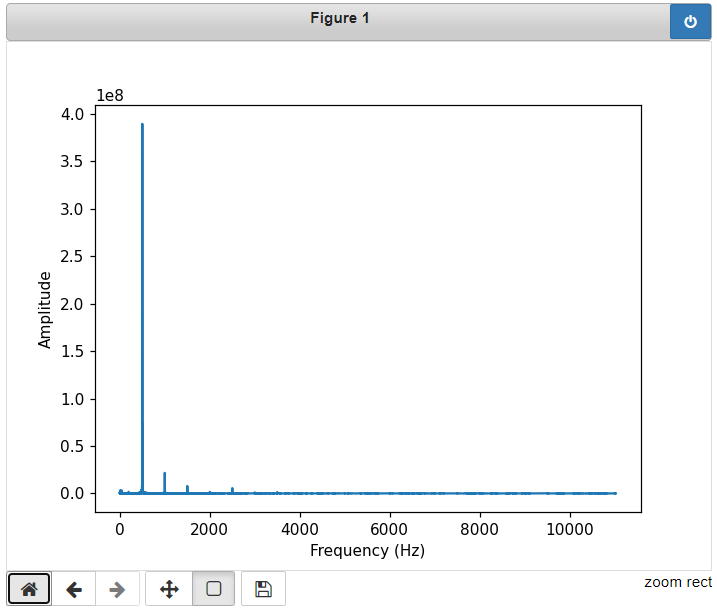 Abb.: FFT Analyse einer 500Hz Aufnahme 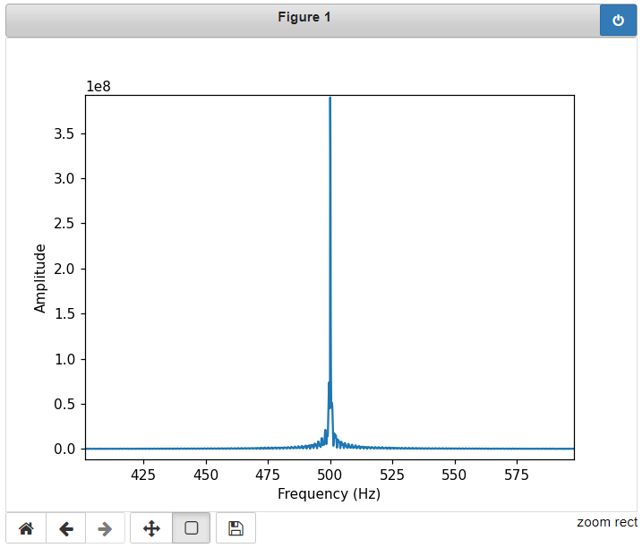 Abb.: Nahaufnahme des größten Peaks der FFT Sound_Track_500Hz.wav Testaufbau zur Positionsbestimmung Zur Durchführung des Positionsbestimmung der Swimming Pixel wird ein Testaufbau konzipiert. Dieser wurde bereits in der vorherigen Projektgruppe "Floating Pixels - Positionsbestimmung" beschrieben und soll nun in leicht abgeänderter Form als Basis für den Testaufbau in diesem Projekt dienen. Der Aufbau besteht aus einem PC als Host, sowie zwei Lautsprechern, welche sich in einem definierten Abstand rechts und links des Hosts befinden. Beide Lautsprecher senden ein Schallsignal aus, welches mit dem Mikrofon auf dem Swimming Pixel aufgezeichnet wird. Über die Laufzeitdifferenz der beiden Schallsignale von den Lautsprechern kann die Position des Pixels mittels Lateration berechnet werden. In der nachfolgenden Abbildung ist der Aufbau dargestellt. 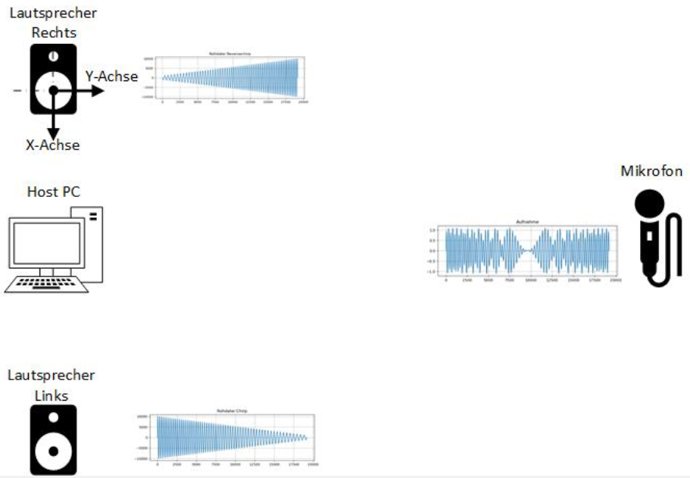 Abb.: Testaufbau zur Positionsbestimmung Als Schallsignal wird ein Upsweep und ein Downsweep verwendet. Der Upsweep wird vom rechten Lautsprecher zeitgleich mit den Downsweep vom linken Lautsprecher gesendet. Zur Erzeugung der beiden Schallsignale wird das Python Notebook Chirp_Stereo entwickelt. Die Frequenz, die Dauer des Signals sowie die Amplituden-Variation muss in dem Code je nach Test im hörbaren Bereich oder im Ultraschall Bereich angepasst werden. Wie in der nachfolgenden Abbildung ersichtlich, werden zwei gegenläufige Chirp Signale erzeugt und als Stereo-Audio-File abgespeichert. 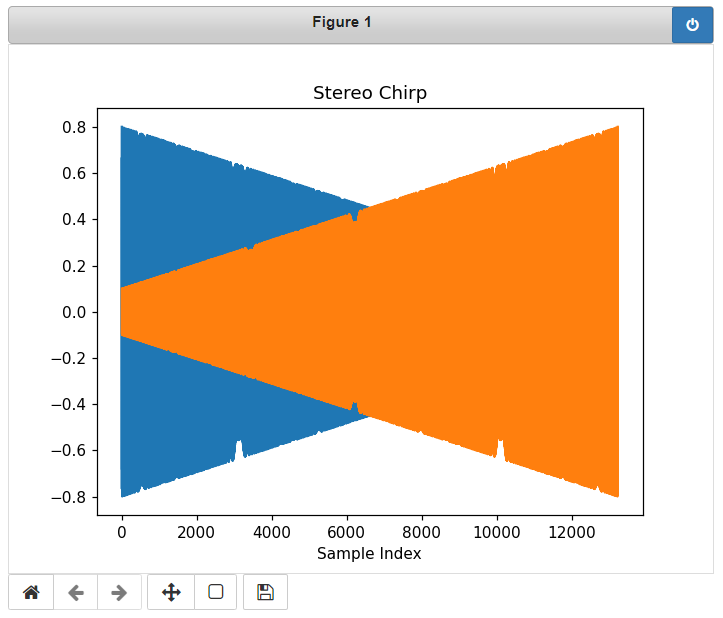 Abb.: Stereo Chirp Soundsignal Stereo_Chirp.wav Positionsbestimmung mittels Lateration Zur Berechnung der Position der Swimming Pixel wird das Verfahren der Lateration verwendet. In der nachfolgenden Abbildung ist dies erklärt. Die beiden Punkte C1 und C2 stellen jeweils einen Lautsprecher dar. Diese befinden sich in einem definierten Abstand U voneinander. Der Punkt P beschreibt beispielhaft einen Swimming Pixel, welcher sich an der noch unbekannten Positon (x/y) befindet. Die beiden Radien r1 und r2 der Kreise beschreiben die Wegstrecke, die ein Schallsignal von dem entsprechenden Lautsprecher zurückgelegt hat. Um die Positionen der Teilnehmer in dem System eindeutig zu definieren, wird der Ursprung des Koordinatensystems in den linken Lautsprecher gelegt. 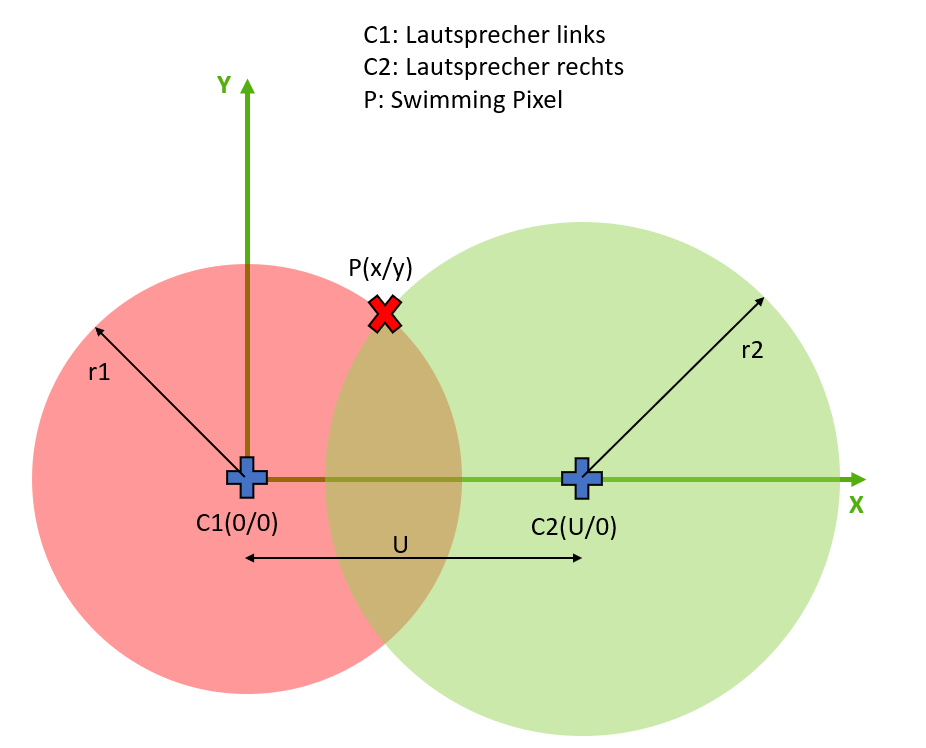 Abb.: Berechnung mittels Lateration Die Berechnung der Koordinaten des Pixels (x/y) erfolgt über die nachfolgenden Zusammenhänge. Hierbei sind die Größen r1, r2 und U bekannt. Die Werte für x und y sollen berechnet werden. Da bei der Berechnung des y-Werts nur der positive Wert relevant ist, wird der negative Wert der Wurzel nicht weiter berücksichtigt. 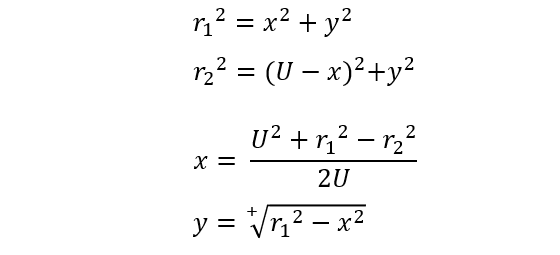 Abb.: Formeln zur Berechnung der Position des Pixels Kreuz-Korrelation Zur Berechnung der Wegstrecke der beiden Schallsignale, wird das Verfahren der Kreuz-Korrelation verwendet. In der Signalanalyse wird dieses Verfahren zur Beschreibung der Korrelation zweier Signale x(t) und y(t) bei unterschiedlicher Zeitverschiebung t zwischen den beiden Signalen eingesetzt. In diesem Projekt wird die Kreuz-Korrelation dafür verwendet die Position des Upsweeps und des Downsweeps in dem vom Mikrofon aufgezeichneten Audiofile zu finden. Anhand der vergangenen Zeit kann somit die Wegstrecke der einzelnen Schallsignale berechnet werden. Die Kreuz-Korrelation wird zunächst für Test-Zwecke in einem Jupyter Notebook programmiert. Der Programmcode ist in dem Ordner Python_Kreuzkorrelation abgespeichert. In den nachfolgenden Abbildungen ist zunächst die vom Mikrofon aufgezeichnete Audio dargestellt. 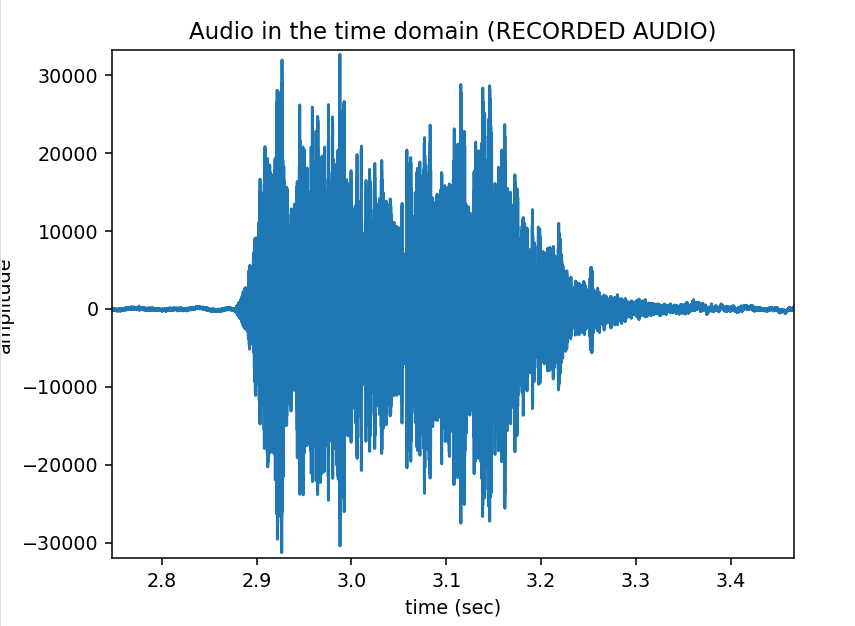 Abb.: Audio-Aufnahme des Stereo-Chirps Da sich der Upsweep sowie der Downsweep in der aufgezeichneten Audio Datei überlagern, sind diese nicht mehr eindeutig ersichtlich. Es lässt sich dennoch gut vermuten, wo sich diese in dem Audiofile befinden. Da diese Audio Datei mit dem Mikrofon aufgezeichnet wird sind zudem auch kleinere Störfaktoren sowie ein geringes Rauschen vorhanden. Zur Bestimmung der Position des Upsweeps und des Downsweeps wird nun die Kreuz-Korrelation angewendet. Das Vorgehen wird hierbei in zwei Schritte unterteilt. Im ersten Schritt wird zunächst die Kreuz-Korrelation mit dem Upsweep bestimmt, im nachfolgenden Schritt wird die Kreuz-Korrelation mit dem Downsweep berechnet.  Abb.: Upsweep 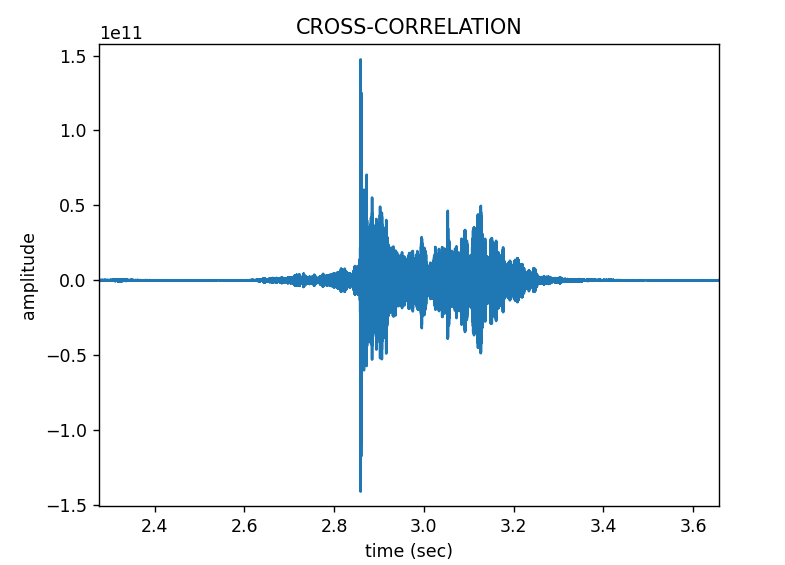 Abb.: Kreuz-Korrelation des Upsweeps in der Audio-Aufnahme des Stereo-Chirps  Abb.: Downsweep 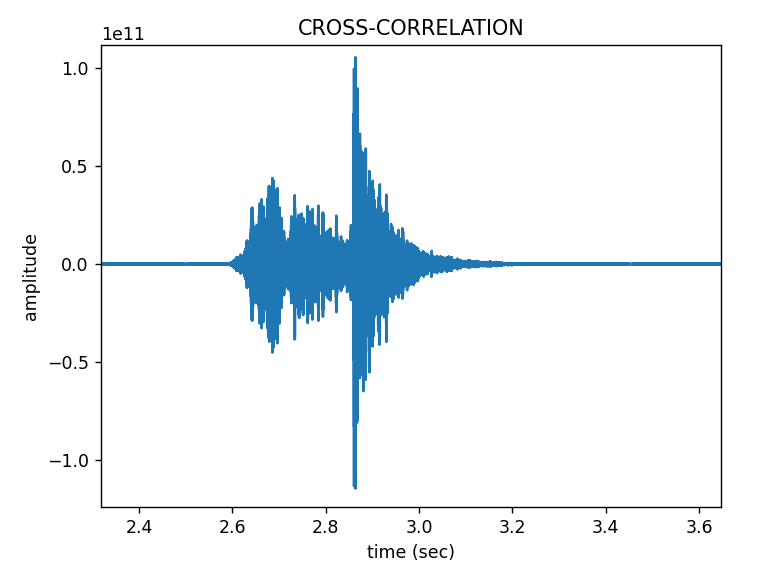 Abb.: Kreuz-Korrelation des Downsweeps in der Audio-Aufnahme des Stereo-Chirps Anhand der Position des Maximums der jeweiligen Kreuz-Korrelation, kann ein Zeitpunkt berechnet werden. Der Zeitpunkt ist hierbei die vom Start der Audio-Aufnahme vergangene Zeit zur Position des jeweiligen Sweeps. In der nachfolgenden Abbildung ist die zeitliche Differenz der beiden Sweep Signale in der aufgezeichneten Audio-Datei berechnet.  Abb.: zeitliche Differenz des Up- und Downsweeps Unter Berücksichtigung der Schallgeschwindigkeit von 343,421 m/s bei 20°C, kann die Wegdifferenz der beiden Sweep Signale berechnet werden. 343,421m/s * 0,004421s = 1,518 m Mit diesen Versuchen wird in der Konzeptentwicklung die grundsätzliche Funktion der Positionsbestimmung mittels Sound bestätigt. Im Kapitel Ausgewählte Lösung wird die finale Umsetzung des Projekts vorgestellt. Hierbei werden alle Programm Codes vereint, als Netzwerkprotokoll wird anstelle HTTP das Protokoll MQTT verwendet. Der Programm Code für den PC wird in einem Python Skript zusammengefasst. Das Programm für den ESP32 wird in C in Visual Studio Code mit der PlatformIO geschrieben. Da eine Bestellung der einzelnen Bauteile wie zum Beispiel der Hochtöner ect. nicht möglich war, werden alle weiteren Versuche mit privater Hardware umgesezt. Sammlung der verwendeten Programmcodes in der Konzeptentwicklung: Client HTTP (ESP32): data/Code_Client_1.zip & data/Code_Client_2.zip Server HTTP (PC): data/Code_Server.zip Python FFT: data/Python_FFT.zip Python Chirp Stereo: data/Chirp_Stereo.zip Python Kreuz-Korrelation: data/Python_Kreuzkorrelation.zip |
| Mit Unterstützung von Prof. J. Walter | Wintersemester 20/21 |